When calculating the activation for one layer, you first need to calculate the quantity:
z(l)=Θ(l)a(l−1)
This is called the weighted input to the neurons in layer l.
So much for the feed-forward phase.
Cost function
We can think of neural networks as a class of parametric non-linear functions from a vector x of input variables to a vector y of output variables. So we can find weights (parameters) as in polynomial curve fitting by minimizing the sum-of-squares error function. So we define a cost function J as
J(w)=21n=0∑N∥y(xn,w)−tn∥2
Where N is the number of training examples, tn is the desired output for the training sample n, and y(xn,w) is the calculated output for the corresponding sample. Notice as the cost function is considered dependent only on weights and not on inputs and/or ground truth, as they are given and cannot be changed.
To use the gradient descend, we need to calculate the partial derivatives ∂w∂Jn for a single training example and then recover the ∂w∂J by averaging over the entire training set. The backpropagation algorithm will be used to calculate such derivatives.
Backpropagation
Errors
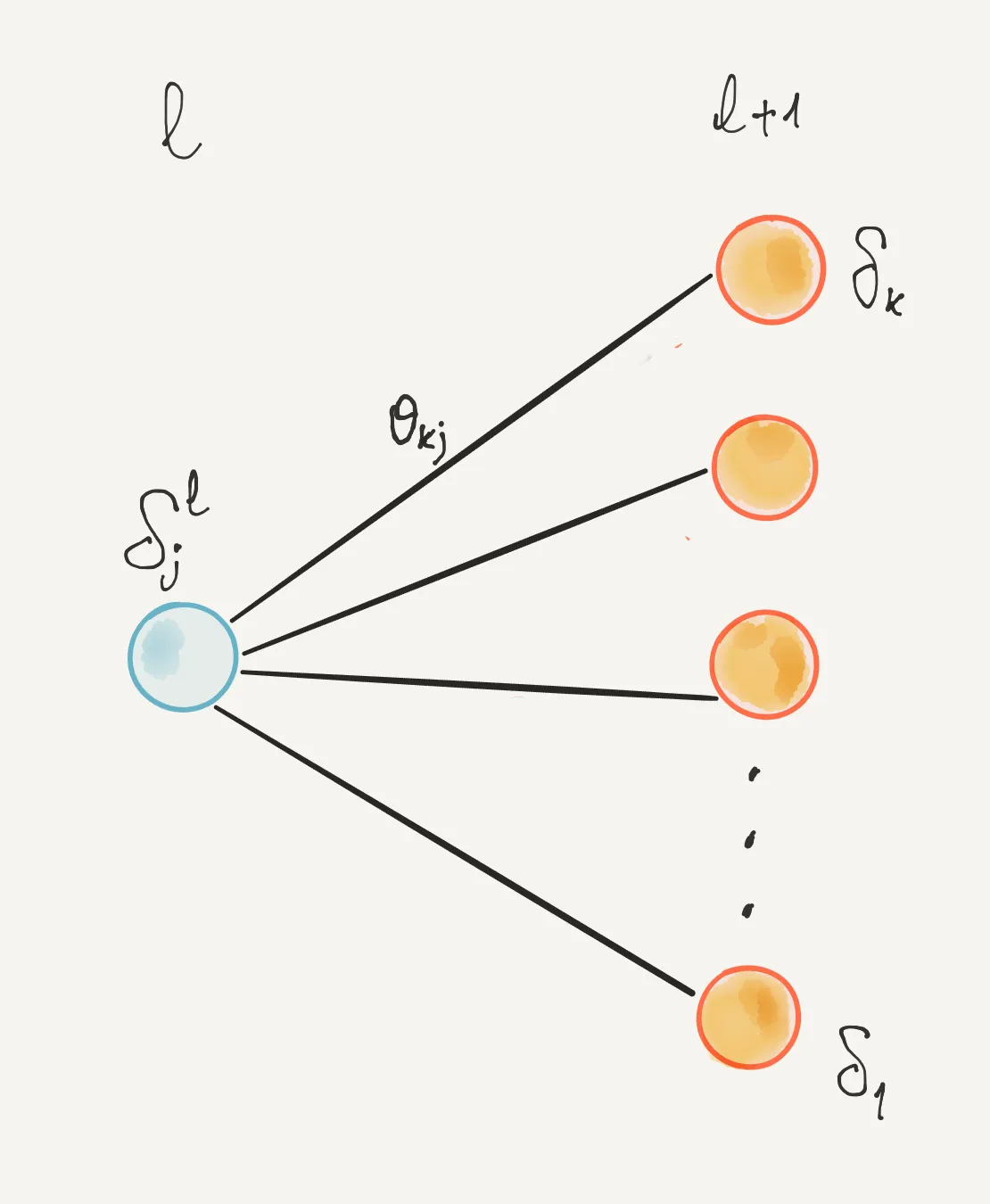
Consider the idea to change the weighted input for the neuron jth in layer l of a small quantity Δzj(l). The neuron will output g(zj(l)+Δzj(l)) instead of
g(zj(l)), causing an overall change to cost J of the amount ∂zj(l)∂JΔzj(l)
If the rate of change of the cost w.r.t. zj(l) is low, then for a small Δzj(l) the cost won’t change too much. In this case, we say the neuron is nearly optimal. So the quantity ∂zj(l)∂J measures, somehow, how much the neuron is not optimized, and we call it the errorδj(l) of the neuron. So by definition, we have:
δj(l)≡∂zj(l)∂J
Varying zj(l) while keeping all other things fixed has some repercussions on the next layer. For a neuron k in layer (l + 1) one can write using the chain rule:
∂zj(l)∂J∣k=∂zk(l+1)∂J∂zj(l)∂zk(l+1)
Which is to say: the contribution of neuron k at the rate of change of cost J caused by neuron j (in the previous layer) is how the cost changes with regards to the weighted sum of neuron k, multiplied for how that said weighted sum changes with regards to the weighted sum of neuron j (chain rule differentiation of function composition).
We can then sum up all the contributions at the level l+1 and state the following:
∂zj(l)∂J=k∑∂zk(l+1)∂J∂zj(l)∂zk(l+1)
This is the most important equation of backpropagation, as it put in relation the error δj(l) with the errors in the next layer. We can rewrite it as:
∂zj(l)∂J≡δj(l)=k∑δk(l+1)∂zj(l)∂zk(l+1)
Regarding the quantity ∂zj(l)∂zk(l+1), we can calculate it starting from the following equation: